后裔收集器是专门为淘宝卖家准备的人工智能收集软件。使用这个软件,可以帮助卖家收集淘宝上的相关数据,比如买家评论、商品信息等等。很方便,所以有需要的用户,快来下载体验吧!
软件功能
1.可视化点击,一键收集网页数据
一路拖拽点击,无需开发任何一个对技术一无所知的人都可以使用的web数据采集器。
2.收藏和导出都是免费的,免费使用没有限制。
免费采集软件,导出数据不限数据可以导出到本地文件,发布到网站和数据库等。
3.它可以在后台运行,并实时显示速度。
您可以将软件切换到后台运行,而不会干扰您的其他前台工作。浮动窗口可以实时查看采集速度和数据。
4.所有平台,Win/Mac/Linux都可用
与其他采集器不同,后羿支持所有操作系统版本更新和功能升级,实现所有平台同步。
处理说明
步骤1:创建一个采集任务。
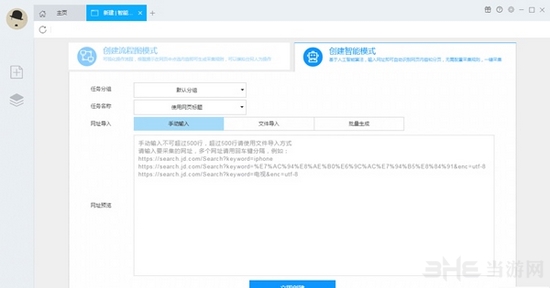
1)启动后羿采集器,进入主界面,选择自定义采集,点击创建任务按钮,创建“自定义采集任务”
2)输入百度搜索的网址,包括三种方式
1.手动输入:直接在输入框中输入网址,多个网址必须用新行隔开。
2.单击从文件中读取:用户选择存储URL的文件。文件中可以有多个URL地址,地址需要断掉。
3.批量添加方法:通过添加和调整地址参数生成多个常规地址。
第二步:定制收购流程。
1)点击创建,自动打开第一个URL,进入自定义设置页面。默认情况下,已经创建了开始、打开网页和结束的进程块。模板的底部区域用于拖放到画布中以生成新的流块;在打开的网页中点按“属性”按钮,以修改打开的URL。
2)添加输入文本流块:将底部模板区域中的输入文本块拖放到打开的网页块的后面附近。当阴影区域出现时,可以松开鼠标,这时会自动连接,添加完成。
3)生成一个完整的流程图:通过模仿上面添加输入文本流程块的拖拽过程,添加一个新块:
关键步骤块设置介绍
第二步:定时等待之前打开的网页完成。
第三步:点击输入框中的Xpath属性按钮,点击属性菜单中的图标点击网页中的输入框,点击输入文本属性按钮,在菜单中输入要搜索的文本。
第四步:设置点击开始搜索按钮,点击元素的xpath属性按钮,点击菜单中的点击图标,然后点击网页中的百度按钮。
第五步:设置循环加载下一个列表页面。在循环块内部的循环条件块中设置详细的条件,点击这里的操作按钮,选择单个元素,然后在属性菜单中点击该元素的xpath属性按钮,如上图在网页中点击下一步按钮。循环次数属性按钮可以默认设置为0,即不限制下一页的点击次数。
第六步:设置循环提取列表页面中的数据。在loop块内部的loop condition块中设置详细的条件,在这里点击action按钮,选择未固定元素列表,然后在attribute菜单中点击elements的xpath属性按钮,然后在网页中点击两次,提取第一个和第二个元素。默认情况下,“循环次数”属性按钮可以设置为0,即列表中的充电字段数量不受限制。
第7步:单击下一页按钮,单击元素xpath属性按钮,并使用当前循环中的元素选择xpath选项。
第八步:同样用于设置网页加载的等待时间。
第九步:设置从列表页面提取的字段规则,在属性按钮中点击使用循环按钮中的元素,在使用循环选项中选择元素。单击元素模板属性按钮,通过单击字段表中的加减来添加和删除字段。单击加号将鼠标移动到网页元素,然后单击选择它。
4)单击开始收集开始收集。
步骤3:数据采集和导出
1)采集任务正在运行。
2)收集完成后,选择“导出数据”将所有数据导出到本地文件。
3)选择“导出方式”导出采集的数据,这里可以选择excel作为导出格式。
4)采集的数据导出后,出现下图
更新内容
修复某些情况下的文件下载问题。
修复某些情况下生成{过度} {过滤}的问题




 YT Downloader
YT Downloader 销大师
销大师 1qvid
1qvid 豆伴豆瓣账号备份工具
豆伴豆瓣账号备份工具 短视频无水印提取小工具
短视频无水印提取小工具 Namo WebEditor汉化版
Namo WebEditor汉化版 抓图小助手
抓图小助手 华视安邦监控软件
华视安邦监控软件